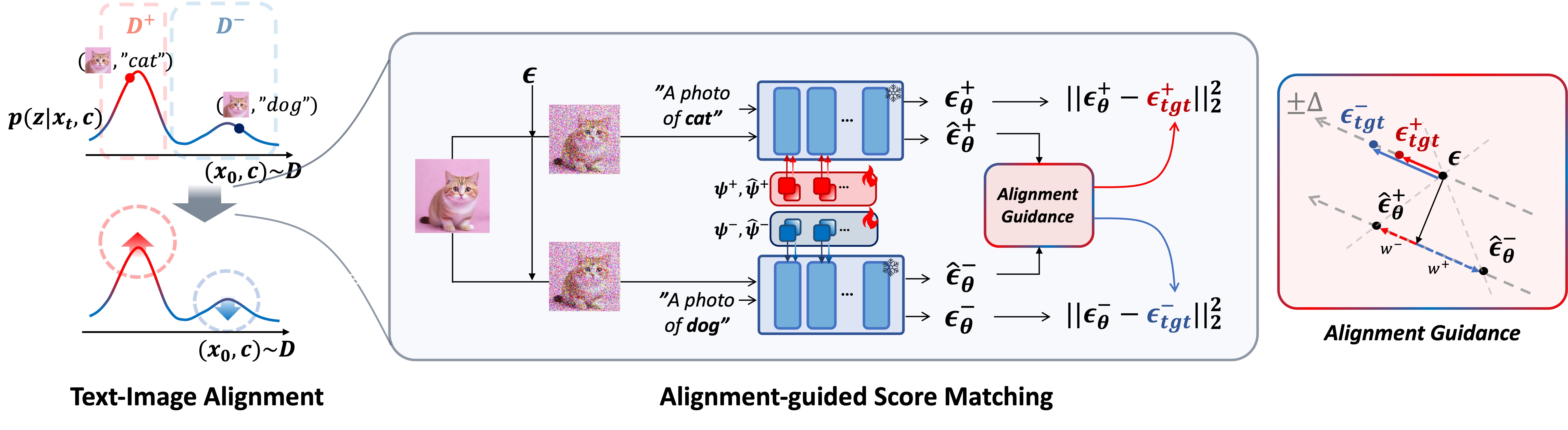
Method Overview
AGSM treats text-image alignment as a reward-free preference problem inside the diffusion score-matching objective.
It first estimates an intrinsic alignment reward from denoising likelihood, normalizes text candidates with a Plackett–Luce model, and then modifies the score-matching target with bounded alignment guidance.
AGSM increases alignment rewards for positive pairs and decreasing those for negative pairs.
$\epsilon_\theta^+$, $\epsilon_\theta^-$ are conditioned on positive, negative soft tokens $(\psi^+, \psi^-)$.
Target noise is adjusted using alignment guidance derived from implicit-reward–weighted EMA predictions $(\hat\epsilon_\theta^+, \hat\epsilon_\theta^-)$.
From Contrastive Pushes[1] to Score Guidance
- Reward-free alignment signal. Derive alignment rewards from the diffusion model’s own denoising likelihood, without external reward models.
- Normalized preference guidance. Use a Plackett-Luce formulation to model alignment probabilities.
- Target-level score correction. Shift the score-matching target rather than directly maximizing negative pairs' denoising errors.
Dual Soft Tokens
- Architectural separation. \(\psi^+\) and \(\psi^-\) decouple positive and negative alignment regions.
- Cleaner loss design. The split objective assigns separate score-matching targets to positive and negative pairs, enabling bounded negative guidance instead of over-optimizing negative pairs.
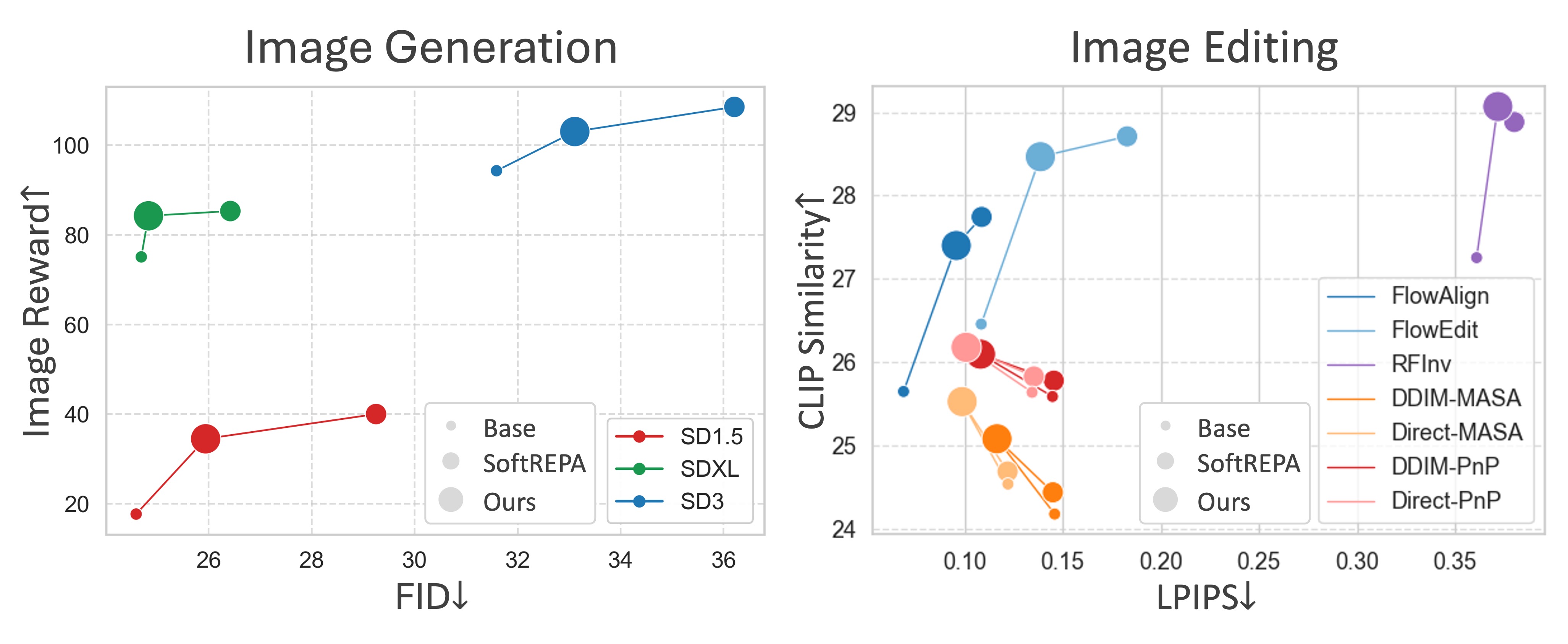
- Ablation-backed benefit. With the same total token budget, the dual-token design outperforms positive-only and shared-token variants on alignment metrics.